Lesson 13
Calcolo numerico per la generazione di immagini fotorealistiche
Maurizio Tomasi maurizio.tomasi@unimi.it
Syntactic and Semantic Analysis
Syntactic and Semantic Analysis
In the last lesson, we saw how to implement a lexical analysis of a source file that defines a 3D scene.
The lexer we implemented reads a sequence of characters from a stream (a file) and produces a sequence of tokens as output.
Today’s task is to interpret the sequence of tokens (syntactic analysis) and from this build a series of objects of type
Shape,Material, etc. in memory (semantic analysis).
Syntactic Analysis
The syntax of a language can be divided into categories depending on the peculiarities of its syntax and how the tokens are concatenated: LL(n), LR(n), GLR(n), LALR(n), etc.
Each of these families requires specific algorithms for parsing, and unfortunately, algorithms that work well for one family do not necessarily work well for others!
Our language is of type LL(1), like Pascal but unlike C++, and the algorithm for analyzing LL grammars is among the simplest.
How to Approach the Problem
Let’s consider this definition:
The definition includes these elements:
- A material;
- A BRDF (
diffuse); - Two pigments (
imageanduniform); - A color, indicated by
<0.7, 0.5, 1>.
Top-Down Approach
However, it is simple to write a function that analyzes the definition of
sky_materialif it can rely on other functions, each of which analyzes only one element.Therefore, we define a function
parse_colorthat interprets a sequence of tokens as a color and returns the correspondingColorobject, a functionparse_pigment, a functionparse_brdf, etc.These functions will have the task of calling each other, one inside the other, so that higher-level functions like
parse_materialcan rely on progressively simpler ones likeparse_color.
parse_color
def expect_symbol(stream: InputStream, symbol: str) -> None:
"""Read a token from `stream` and check that it matches `symbol`."""
token = stream.read_token()
if not isinstance(token, SymbolToken) or token.symbol != symbol:
raise parser_error(token, f"got '{token}' instead of '{symbol}'")
# Don't bother returning the character: we were already expecting it
def expect_number(stream: InputStream, scene: Scene) -> float:
"""Read a token from `stream` and check that it is either a literal number or a variable.
Return the number as a ``float``."""
token = input_file.read_token()
if isinstance(token, LiteralNumberToken):
return token.value
elif isinstance(token, IdentifierToken):
variable_name = token.identifier
if variable_name not in scene.float_variables:
raise GrammarError(token.location, f"unknown variable '{token}'")
return scene.float_variables[variable_name]
raise GrammarError(token.location, f"got '{token}' instead of a number")
# This parses a list of tokens like "<0.7, 0.5, 1>". Note that functions
# with name "expect_*" only read *one* token, while functions named
# "parse_*" read more than one token.
def parse_color(stream: InputStream) -> Color:
expect_symbol(stream, "<")
red = expect_number(stream)
expect_symbol(stream, ",")
green = expect_number(stream)
expect_symbol(stream, ",")
blue = expect_number(stream)
expect_symbol(stream, ">")
# Create the "Color" object *immediately* (not something a real-world
# compiler will do, but our case is simpler than a real compiler)
return Color(red, green, blue)parse_pigment
def parse_pigment(stream: InputStream) -> Pigment:
# Examples: uniform(<0.7, 0.5, 1>)
# checkered(<0.3, 0.5, 0.1>, <0.1, 0.2, 0.5>, 4)
# image("bitmap.pfm")
keyword = expect_keywords(stream, [
KeywordEnum.UNIFORM,
KeywordEnum.CHECKERED,
KeywordEnum.IMAGE,
])
expect_symbol(stream, "(")
if keyword == KeywordEnum.UNIFORM:
color = parse_color(stream)
result = UniformPigment(color=color)
elif keyword == KeywordEnum.CHECKERED:
color1 = parse_color(stream)
expect_symbol(stream, ",")
color2 = parse_color(stream)
expect_symbol(stream, ",")
num_of_steps = int(expect_number(stream))
result = CheckeredPigment(color1=color1, color2=color2, num_of_steps=num_of_steps)
elif …: # Other pigments
…
expect_symbol(stream, ")")
return resultSemantic Analysis and Beyond
A full-blown compiler like GCC would use the result of semantic analysis to build an Abstract Syntax Tree (AST).
The AST would be passed to the optimizer and then to the code generator, whose purpose is to output machine code.
Question: if you declare a variable like
do you think GCC needs to allocate this memory during the compilation? If so, at which stage? (Lexing, parsing, AST optimization, machine code emission, …)
Semantic Analysis and Beyond
Our “compiler” is very simple, and as soon as the syntactic analysis understands that a variable/material/shape/observer is being defined, it immediately creates a corresponding object in memory (e.g.,
Color).In some sense, our compiler is an interpreter, because it “executes” the code as soon as it is processed by the parser.
This is a huge simplification for us! Even traditional “interpreters” like Python and Julia have a compilation stage which precedes the execution stage.
Types of Grammars
LL(n) Grammars
In an LL(n) grammar, tokens are analyzed “from left to right,” that is, in the order in which they are produced by the lexer.
The number n in the notation LL(n) indicates that n look-ahead tokens are needed to correctly interpret the syntax: that is, the n subsequent tokens are examined to interpret the current token (similar to how
unread_charworks in our lexer).Consequently, our format for describing scenes is of type LL(1) because:
- The syntax is analyzed by reading one token after another, in order;
- It may be necessary to check the type of the one token following the current one, but no more than that.
Why LL(1)?
Let’s now explain in which contexts it is necessary to use look-ahead.
Consider this definition:
float clock(150)In this case, look-ahead is not necessary:
- The first token is the keyword
float, which indicates that a variable is being defined; - Therefore, our compiler knows that the next tokens will necessarily
be the identifier, the symbol
(, a numeric literal, and the symbol).
- The first token is the keyword
Declaring a float
# Read the first token of the next statement. Only a handful of
# keywords are allowed at the beginning of a statement.
what = expect_keywords(stream, [KeywordEnum.FLOAT, …])
if what == KeywordEnum.FLOAT:
# We are going to declare a new "float" variable
# Read the name of the variable
variable_name = expect_identifier(stream)
# Now we must get a "("
expect_symbol(stream, "(")
# Read the literal number to associate with the variable
variable_value = expect_number(stream, scene)
# Check that the statement ends with ")"
expect_symbol(stream, ")")
# Done! Add the variable to the list
variable_table[variable_name] = variable_value
elif …: # Statements other than "float …" can be interpreted here
…Why LL(1)?
Let’s consider these definitions:
We must write a function
parse_planethat calls a functionparse_transformation.But the transformation is problematic: after
…100])we cannot tell if the definition is complete or if the*symbol (composition) follows. In the latter case,parse_transformationwould still have work to do!
# Start from the identity matrix
result = Transformation()
while True:
# For simplicity, let's consider just two kinds of transformations
transformation_kw = expect_keywords(stream, [
KeywordEnum.TRANSLATION,
KeywordEnum.ROTATION_Y,
])
if transformation_kw == KeywordEnum.TRANSLATION:
expect_symbol(stream, "(")
result *= translation(parse_vector(stream, scene))
expect_symbol(stream, ")")
elif transformation_kw == KeywordEnum.ROTATION_Y:
expect_symbol(stream, "(")
result *= rotation_y(expect_number(stream, scene))
expect_symbol(stream, ")")
# Peek the next token
next_kw = stream.read_token()
if (not isinstance(next_kw, SymbolToken)) or (next_kw.symbol != "*"):
# Pretend you never read this token and put it back!
# This requires to alter the definition of `InputStream`
# so that it holds the unread tokens as well as unread characters
stream.unread_token(next_kw)
breakEBNF Grammars
Describing a grammar
By “grammar” we mean the set of lexical, syntactic, and semantic rules of a language.
From the point of view of syntactic analysis, it should be evident that a parser needs to know at every moment what is the list of tokens admissible at the point where it has arrived in interpreting the source code.
In compiler theory, some notations have been invented to describe the grammar of languages, which are very useful when implementing a lexer or a parser.
EBNF Grammar
The notation we will see is called Extended Backus-Naur Form (EBNF), and is the result of the work of many people, including Niklaus Wirth (the creator of the Pascal language).
We will not provide a full description of EBNF and will just present it in simple terms. It is useful to understand it because often the documentation of programming languages contains their grammar (for example Nim, C# and Kotlin; for Rust they are working on it, while the D manual uses a different syntax).
The next slide shows the entire syntactic structure of our grammar in EBNF format.
EBNF for our format
scene ::= declaration*
declaration ::= float_decl | plane_decl | sphere_decl | material_decl | camera_decl
float_decl ::= "float" IDENTIFIER "(" number ")"
plane_decl ::= "plane" "(" IDENTIFIER "," transformation ")"
sphere_decl ::= "sphere" "(" IDENTIFIER "," transformation ")"
material_decl ::= "material" IDENTIFIER "(" brdf "," pigment ")"
camera_decl ::= "camera" "(" camera_type "," transformation "," number "," number ")"
camera_type ::= "perspective" | "orthogonal"
brdf ::= diffuse_brdf | specular_brdf
diffuse_brdf ::= "diffuse" "(" pigment ")"
specular_brdf ::= "specular" "(" pigment ")"
pigment ::= uniform_pigment | checkered_pigment | image_pigment
uniform_pigment ::= "uniform" "(" color ")"
checkered_pigment ::= "checkered" "(" color "," color "," number ")"
image_pigment ::= "image" "(" LITERAL_STRING ")"
color ::= "<" number "," number "," number ">"
transformation ::= basic_transformation | basic_transformation "*" transformation
basic_transformation ::= "identity"
| "translation" "(" vector ")"
| "rotation_x" "(" number ")"
| "rotation_y" "(" number ")"
| "rotation_z" "(" number ")"
| "scaling" "(" vector ")"
number ::= LITERAL_NUMBER | IDENTIFIER
vector ::= "[" number "," number "," number "]"EBNF Explanation
The symbol
::=defines a grammar element, for example:number ::= LITERAL_NUMBER | IDENTIFIERThe symbol
|represents a series of alternatives (logical or).The symbol
*denotes zero or more repetitions (+indicates one or more):scene ::= declaration*UPPERCASEindicates tokens produced by the lexer,lowercaseidentifies other elements in the EBNF grammar.Recursive definitions are possible:
transformation ::= basic_transformation | basic_transformation "*" transformation
Compiler Error Handling
Error Handling
Our code raises an exception whenever an error is detected in the source code.
It is able to report the row and column of the token where the error was found, which is very useful!
But this execution model requires that compilation terminates at the first error! Modern compilers like
g++andclang++instead continue compilation, looking for subsequent errors.To avoid stopping at the first error, we need to look for a termination token, i.e., a token that is used to terminate a command: once found, we continue from the next token.
Termination Tokens
In the C++ language, two frequently used termination tokens are
;(used to terminate a statement) and}(used to terminate a block of code). For example:In a language like ours, it is not easy to identify a termination token; the best thing would be to require the presence of
;at the end of each statement, as in C++, or to require definitions to be terminated by a newline character (encoded as aTOKEN_NEWLINEtoken).
LLMs and errors
AI agents are LLMs that can operate on a codebase to run tests, make modifications, fire the compiler, etc.
A recent issue is to make error message helpful to AI agents
See for instance this post in the Nim Language Forum: Better error messages would help AI agents
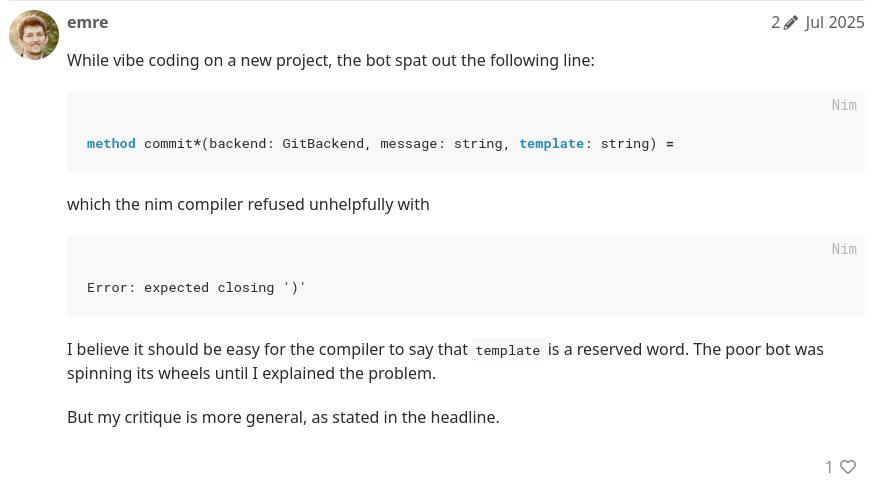
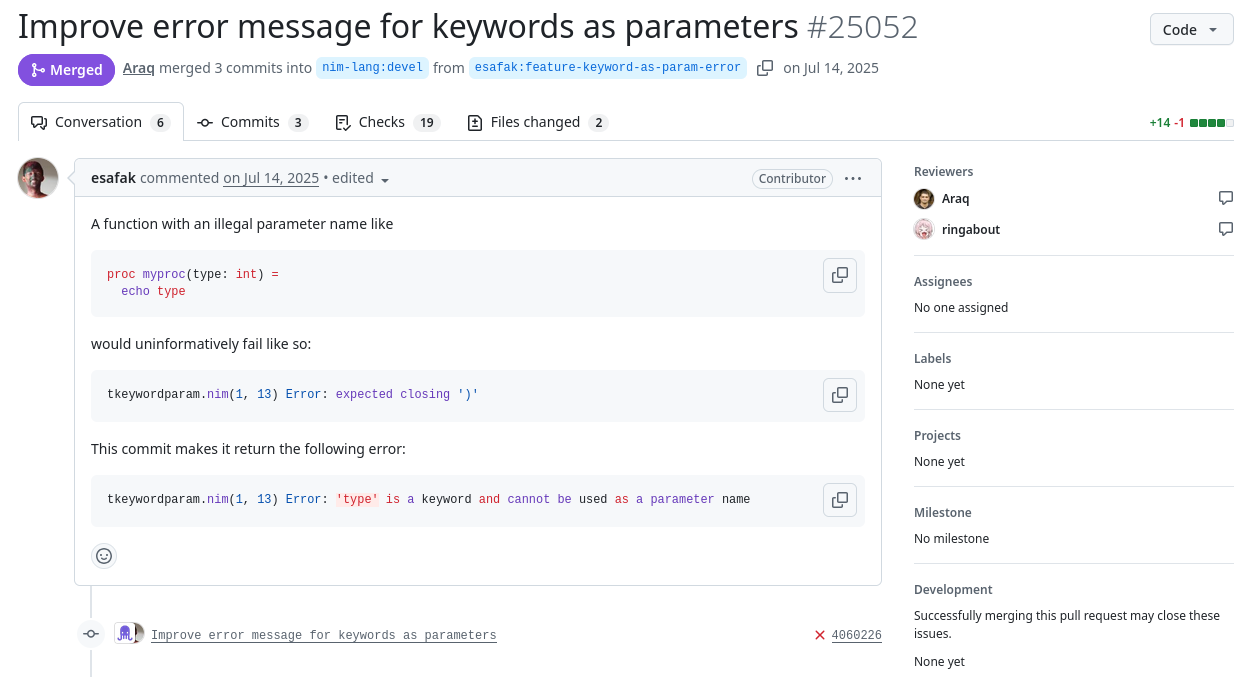
PR#25052 has been successfully merged on July, 14th 2025.
Language Comparison
Compiler Complexity
Producing lists of errors instead of just one error at a time is especially important in cases where the compiler is very slow to execute. This is the case with C++ and Rust.
Our language will be very easy to interpret (it does not have complex semantics, and does not require the creation of an AST or the application of an optimizer): it is therefore not worth worrying about implementing this functionality.
However, let’s take this opportunity to understand why there can be large differences in the compilation speed of languages!
C++ Complexity
The great complexity of C++ is mainly related to
templates and the use of header files.Let’s have a look at some of the problems with the C++ grammar by considering a couple of real-world examples.
First example
Imagine that you have N particle detectors. You want to collect the energy of each event measured by each detector.
The domain is 2D (detectors × events), but it cannot be stored in a matrix: if there is one row per detector, the number of columns will depend on the number of events recorded by each detector.
Thus, we must define a structure that can hold lists of lists:
First example
Using a typed language like C++, we might define
datain this way:Before C++11, this definition was not correct: pre-C++11 compilers would refuse to compile it. Can you guess why?
First example
The problem is that
>>can either be interpreted by the lexer as two tokens (>and>) or one (>>). The following example shows the problem:It is impossible to create the correct token sequence with the approach we have followed, which rigidly separates lexing from parsing.
Only C++11 mandated compilers to accept this syntax: see document N1757, published in 2005. (The C++ language was invented in the 1980s!)
Second example
Let’s move to another example to show an additional difficulty with templates.
Nowadays, the most common CPU architectures are 32-bit and 64-bit, depending on the size of their CPU registers. (This affects how much data the CPU can handle in one pass and how much memory can address.)
Operating Systems and systems libraries like glibc and musl need to define the fields in structures using the most appropriate types for their field.
If we are using C++, we might use templates to define these structures in a smart way.
You are probably familiar with C++ templates using types as parameters:
This means that when you write
the template gets instantiated by substituting
doubleto each occurrence ofTin the definition of thevectorclass.
But you are not limited to types: C++ lets you to use values as template parameters.
This is handy in our case. We can define a structure that mimicks the POSIX
statdatatype:template<bool> struct my_stat; // No `typename T` here, just `bool` // 64-bit case: the value of `bool` is `true` template<> struct my_stat<true> { int64_t st_dev; // Device number int64_t st_ino; // Inode number // ... } // 32-bit case: the value of `bool` is `false` template<> struct my_stat<false> { int32_t st_dev; // Device number int32_t st_ino; // Inode number // ... }
Using the previous definition, we can employ the fact that
size_tis an integer type that is 8-byte wide on 64-bit architectures but just 4-byte wide on 32-bit:In this way, we do not need to use
#ifdefs and macro madness in defining some code that will do the right thing when compiled on 32-bit or 64-bit machines.However, at the syntax level, the
>term in this example makes everything complicated for the parser!
An important quote
I’ve become somewhat infamous about wanting to keep the language [Rust] LL(1) but the fact is that today one can’t parse Rust very easily, much less pretty-print (thus auto-format) it, and this is an actual (and fairly frequent) source of problems. It’s easier to work with than C++, but that’s fairly faint praise. I lost almost every argument about this, from the angle brackets for type parameters [emphasis added] to the pattern-binding ambiguity to the semicolon and brace rules to … ugh I don’t even want to get into it. The grammar is not what I wanted. Sorry.
Graydon Hoare, creatore del linguaggio Rust.
Solutions to the problem (1/2)
When templates were introduced in C++, it was a terrible choice to use
<and>as symbols because (1) they were already used as comparison operators, and (2) the operators<<and>>already existed.C# suffers from the same problem, but it is less severe (in C# templates are called generics):
- To distinguish between the case where
>>should be interpreted as two tokens or one, the rule is that if the next token is(,),],:,;,,,.,?,==, or!=, then it should be interpreted as two tokens, otherwise one; - Inside
<>you can only specify types, not expressions likea > b.
- To distinguish between the case where
Pascal, Nim, and Kotlin use
shlandshrinstead of<<and>>.
Solutions to the problem (2/2)
The D language instead uses a different, easier-to-parse syntax for templates, and in the previous example would write
Rust uses
<>like C++, but to remove the ambiguity it requires writing::<in expressions:
Example: variables
In C/C++, variable declarations are complicated because the identifier containing the variable name is placed in the middle of the type:
which declares an array of 100 variables of type
int.The tokens that define the type are
int,[,100, and], and are located both to the left and right of the variable name: this is complicated for the programmer! (Try to interpret the more complicated case yourself!)
Example: variables
The Go language uses a simpler notation:
The
varkeyword signals to the parser that a variable is being declared.The tokens that define the type are reported all together, after the identifier representing the variable name.
The notation
[100]intfollows the natural order of words: “an array of 100intvalues”, and is easier for the programmer to read (in C you have to read backwards, from right to left).
Example: variables
Go was inspired by Pascal, where variables are listed within a
varclause. The variable name comes first and is clearly separated from the type:This syntax is very easy to interpret: Pascal is in fact designed to be simple and at the same time fast to compile.
Similar ideas are used in the Modula, Oberon, Ada, Nim, and Kotlin languages.
Testing compilers
Testing
Writing tests for a compiler is a very complex matter, because the number of possible errors is practically infinite!
It is not possible to have completely exhaustive tests; you need to be creative and be prepared to add many new tests once users start using your program. (In pytracer I have implemented just the bare minimum, you are encouraged to write more tests!)
If you are curious, in the
clang/test/Lexerdirectory there are the source files used for the tests of only the Clang lexer!
Automatic Compiler Generation
Automatic Generation
There are tools to automatically generate lexers and parsers. These tools require a grammar as input (usually in EBNF form), and produce source code that interprets the grammar.
Two historically important tools are
lexandyacc, which are available today in the open-source versions Flex and Bison (they generate C/C++ code).Lemon generates C code and was used to write the SQL parser used in SQLite.
ANTLR (C++, C#, Java, Python) is the most complete and modern solution.
Keep in mind, however, that most people prefer to write lexers and parsers by hand…
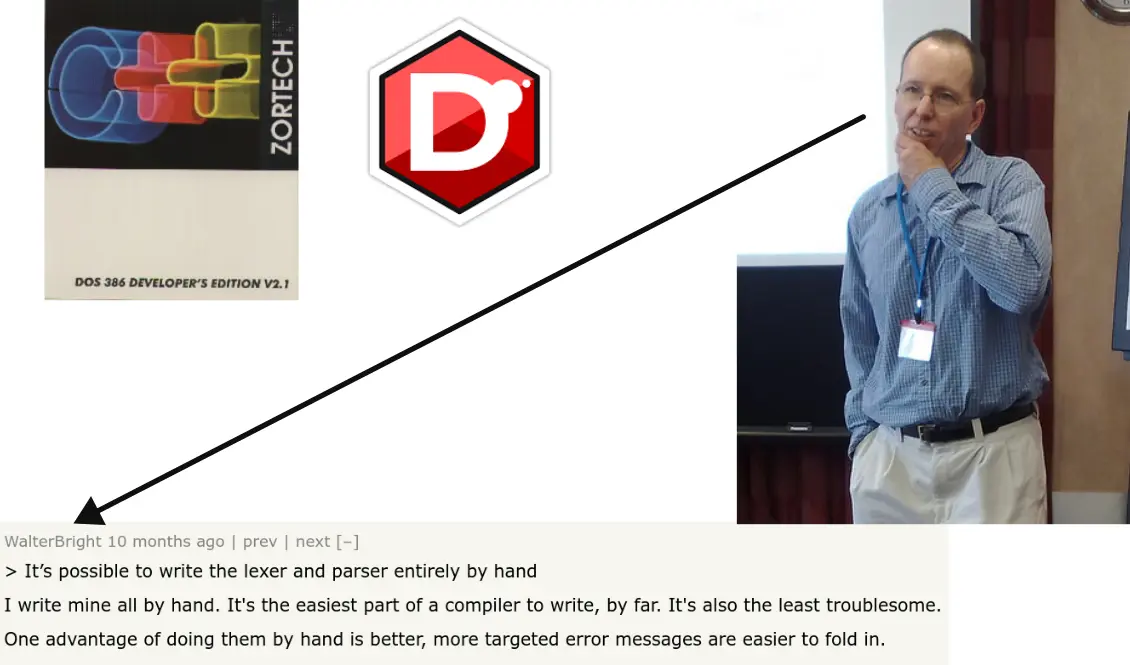
Post by Walter Bright on HackerNews (June, 18th 2025)
Further resources
Wirth’s book Compiler Construction (Addison-Wesley, 1996) is remarkably clear: in a few pages it shows how to implement a compiler for the Oberon language (a language created by Wirth as a successor to Pascal).
A good recent book is “Writing a C compiler” by Nora Sandler, which takes inspiration by Abdulaziz Ghuloum’s seminal paper An Incremental Approach to Compiler Construction (2006).
Today, compilers are considerably more complex due to the necessary integration with development environments (PyCharm, CLion, IntelliJ IDEA, etc.). Watch the video Anders Hejlsberg on Modern Compiler Construction: you will appreciate much more what your IDEs do!
Conclusions
Conclusions
We’ve reached the end of the course!
Once you’ve implemented the parser, you can release version
1.0of your program, sell it to Disney Studios, make a ton of money, and live in luxury for the rest of your life!If, however, you intend to continue working as a «physicist», before concluding, it’s good to review what we’ve learned in this course and how it can be useful to you in the future, even if it doesn’t involve rendering 3D scenes…
The Most Important Skills
Write code little by little, verifying each new feature with tests: don’t write an entire program from top to bottom without ever testing or compiling it!
Automate tests using CI builds.
Use version control systems to track changes.
Be organized in the use of issues, pull requests,
CHANGELOGfiles, etc.Decide from the start which license to use to release your code.
Document your work (
README, docstrings…).Learn to use a proper IDE!
Simulation Codes
In the specific case of simulation codes, choose your random number generator carefully!
It’s important that the user of your code can specify the seed and, if the generator allows it, the sequence identifier: this allows for the repeatability of simulations, which helps a lot during debugging. (As a testament to this, have a look at this PR…)
If you have to run many simulations, use the ability of modern computers to perform calculations in parallel. In the simplest cases, it’s enough to use GNU Parallel.
Extensibility
It’s very likely that the users of the programs you develop will try to use them in contexts you hadn’t foreseen.
Therefore, it’s important that your program has a certain degree of versatility.
(However, don’t overdo it: the more versatile a program is, the more complex it is to write, and therefore you risk never releasing version 1.0!)
I/O: Use Standards!
In our project, we implemented the ability to read the scene from a file. This is much more versatile than the simple
democommand!Similarly, some of you have made it so that your program saves images in multiple formats: not just PFM, but also PNG, JPEG, etc.
In general, it’s good to rely on widespread formats (PNG, JPEG) rather than obscure formats (PFM) or even ones you invent yourself! This last option is viable only if there are no suitable formats (as is the case with the scene description language we invented).
Exams
How to Register for the Exam (1/2)
Scheduling the date: The exam is individual. To set the date for your interview, please send me an email: we will agree on a date individually, even for members of the same group.
Mandatory registration requirement: In order to take the exam, it is mandatory to already be registered for an official exam session on SIFA. No exceptions will be made, and it is not possible to take the exam “provisionally” and record the grade at a later time.
Why this rule? For transparency and security. Your grade is officially recorded online on SIFA immediately at the end of the interview. This prevents any risk of lost grades, career delays, or future disputes.
How to Register for the Exam (2/2)
The timing rule (Pay attention to dates): The system does not allow grades to be recorded for future exam sessions. Consequently, you can only take the exam on the exact date of the session you are registered for or on the following days, never before the official session date.
SIFA Deadlines: Please remember that the SIFA system closes registrations automatically a few days before the exam date. Check the deadline well in advance so you don’t get locked out.
My advice: Register now to the first exam session available on SIFA!
