Laboratorio di TNDS – Lezione 1
Maurizio Tomasi (maurizio.tomasi@unimi.it)
Martedì 23 settembre 2025
Introduzione al corso
Queste slides
All’inizio di ogni sessione di laboratorio mosterò alcune slides che riprendono alcuni concetti già visti a lezione.
Queste slides sono disponibili all’indirizzo ziotom78.github.io/tnds-tomasi-notebooks, e sono navigabili.
Se vi è più comodo, potete ottenere una versione PDF producendola da soli: basta aggiungere
?print-pdfalla fine della URL e stampare la pagina da browser in un file PDF (vedi le istruzioni dettagliate).

Avvertenze generale
Non fare copia-e-incolla da slide come queste! Trascrivere a mano il codice è più utile, perché vi consente di notare alcune sottigliezze sintattiche (es., dove vengono usati i punti e virgola). In generale, trascrivere codice è un ottimo allenamento per imparare a scrivere programmi.
Create un segnalibro per il sito https://cppreference.com/, è indispensabile quando si programma in C++:
Contiene la documentazione completa del linguaggio, suddivisa nelle varie versioni (C++11, C++14, C++17, C++20, C++23…)
Contiene la documentazione e gli esempi d’uso per tutte le funzioni della libreria standard del C++
Configurare il compilatore
Cosa molto importante da fare, una volta per tutte (vedi questo link)
Il compilatore di default sulle macchine del laboratorio è molto vecchio (8.5, del 2021), ma è disponibile una versione più aggiornata (14.2, del 2025)
È sempre meglio usare versioni aggiornate dei compilatori, perché i messaggi di errore si fanno sempre più chiari
Configurare il compilatore
Ad esempio, considerate questo programma (sbagliato):
Col compilatore di laboratorio, il messaggio di errore è il seguente:
![]()

Configurare il compilatore
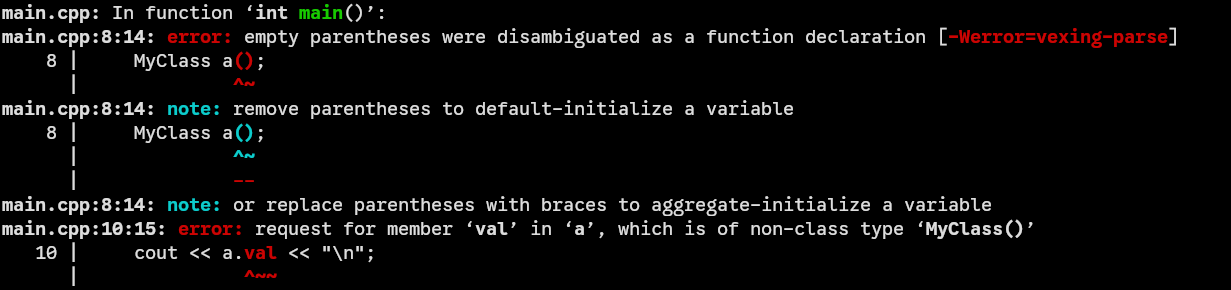
Con il GCC 14 invece, l’errore è il seguente:
![]()
In questo caso il compilatore ha capito che il problema era nella riga
MyClass a(), che non voleva le parentesi (MyClass a, oppureMyClass a{}).
Configurare il compilatore
Potete configurare le macchine del laboratorio perché usino sempre GCC 14 quando vi connettete col vostro utente
Aprite la finestra del terminale ed eseguite il comando
/home/comune/labTNDS_programmi/enable-latest-gccChiudete la finestra del terminale, riapritela ed eseguite
g++ --version. Dovreste vedere questo:$ g++ --version g++ (GCC) 14.2.1 20250110 (Red Hat 14.2.1-7) Copyright (C) 2024 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
“Stile” di programmazione C++
Il C++ è un linguaggio ricchissimo, e insegnanti diversi usano uno stile differente
In questo turno del martedì vi suggerirò delle modifiche al codice proposto da Carminati che impiegano alcune caratteristiche recenti del C++
Quando propongo un’alternativa all’implementazione data a lezione è sempre perché la considero migliore (più performante / meno facile commettere sbagli / più veloce da scrivere)
Non è obbligatorio seguire queste mie indicazioni: usate lo stile C++ che preferite!
Esercizi per oggi
La spiegazione dettagliata degli esercizi si trova qui: carminati-esercizi-01.html.
Gli esercizi sono i seguenti:
- Esercizio 1.0: Calcolo di media, varianza e mediana dei dati letti da un file
- Esercizio 1.1: Codice di analisi con funzioni (variante del precedente)
- Esercizio
1.2: Codice di analisi con
Makefile(variante del precedente) - Esercizio 1.3: Codice di analisi con overloading (variante del precedente)
Dovrete leggere i dati dal file
1941.txt(fate click col tasto destro e salvate il link nella vostra cartella di lavoro).
Esercizi per oggi
$ head -n 4 1941.txt
0.536144578313253
-1.7373493975903613
0.9650602409638556
1.2216867469879515
$ ./esercizio01.1 4 1941.txt
Media = 0.246386
Varianza = 1.37172
Mediana = 0.750602
-1.73735
0.536145
0.96506
1.22169Nota: la varianza è il quadrato della deviazione standard; quest’ultima si indica anche con RMS (Root Mean Square).
Soluzioni attese
È molto importante che verifichiate la corretta esecuzione dei vostri programmi!
State attenti al calcolo della mediana: il 30% degli studenti alla fine del corso consegna esercizi di questa prima lezione in cui la mediana è errata.
Le soluzioni che dovete aspettarvi sono ricavate nella slide seguente. Assicuratevi di ottenere gli stessi valori! (A meno che non usiate il fattore N - 1 anziché N nel calcolo della varianza).
Risultati di riferimento
N = 365:
- Mean : -1.0813335533916488
- Variance : 6.67466568793561 (corrected: 6.693002681583785)
- Standard deviation : 2.5835374369138933 (corrected: 2.587083818043742)
- Median : -0.9156626506024095
N = 10:
- Mean : -1.1889156626506023
- Variance : 4.270508578893889 (corrected: 4.745009532104321)
- Standard deviation : 2.0665208876016448 (corrected: 2.1783042790446703)
- Median : -1.3186746987951807
N = 9:
- Mean : -0.9204819277108434
- Variance : 4.024442831567232 (corrected: 4.527498185513136)
- Standard deviation : 2.0061014011179075 (corrected: 2.12779185671746)
- Median : -0.9Come svolgere gli esercizi
Potete svolgere gli esercizi in uno dei modi seguenti:
- Usando il computer di laboratorio davanti a voi (per chi è in presenza);
- Se avete un portatile con un compilatore C++ installato (ragionevolmente recente), potete svolgere l’esercizio su di esso. Vedete questa pagina per indicazioni su come installare un compilatore C++ adatto.
Computer di laboratorio
Non premete quello che sembra essere il pulsante on/off del monitor, perché in realtà spegne il computer (e manda una segnalazione al centro di calcolo).
Vi consiglio di usare come editor Visual Studio Code, che è installato sui computer del laboratorio. Attenzione però: la configurazione di default di VSCode causa problemi sui computer del laboratorio!
Sistemare VSCode
L’editor preferito dagli studenti è Visual Studio Code, che però sui computer del laboratorio non supporta l’estensione per la programmazione C++ a causa del limitato spazio su disco
Se usate i computer del laboratorio, vi consiglio di usare Geany per editare i vostri programmi. Per configurarlo in modo che supporti il C++ 23, aprite un terminale ed eseguite questa riga:
/home/comune/labTNDS_programmi/setup-geanySe usate il vostro computer portatile personale, VSCode o qualsiasi altro editor vanno benissimo.
Computer del laboratorio (1/2)
Se usate un sistema Linux o Mac OS X, potete usare il comando
sshdal terminale.Digitate
ssh NOMEUTENTE@tolab.fisica.unimi.it, doveNOMEUTENTEè il nome associato alla vostra email.Ad esempio, la mia email è
maurizio.tomasi@unimi.ite quindi il mio nome utente èmaurizio.tomasi:$ ssh maurizio.tomasi@tolab.fisica.unimi.it Last login: Wed Dec 27 06:42:38 2023 from 93.45.84.151 [maurizio.tomasi@lab05 ~]$
Computer del laboratorio (2/2)
Se usate Windows, installate la versione free di MobaXTerm.
Dovete configurare una connessione di tipo «SSH» a
tolab.fisica.unimi.it, specificando il vostro nome utente (solitamentenome.cognome).È un’ottima soluzione anche se volete sviluppare sul vostro computer Windows usando WSL: in questo caso MobaXTerm permetterà di aprire finestre grafiche in cui mostrare i vostri plot, quando introdurremo i comandi grafici.
Suggerimenti vari
Uso di #define
Anziché usare
#defineper definire costanti, preferiteconst:Con
#defineci possono essere problemi con la precedenza degli operatori:
Uso di [[nodiscard]]
Valori di ritorno ignorati
Il C++ mutua dal C una “brutta” abitudine: è possibile ignorare i valori di ritorno delle funzioni senza conseguenze.
In altre parole, si può scrivere codice del genere, e il compilatore lo compilerà senza problemi:
Valori di ritorno ignorati
Il C aveva previsto la possibilità di ignorare valori di ritorno perché molte funzioni restituivano valori non molto “interessanti”
Ad esempio, la funzione
putsstampa a video un messaggio, e restituisceEOFse non è riuscita a farlo:Negli anni ’70 capitava che i computer non avessero monitor e l’output venisse stampato su carta: se la carta finiva o la stampante si inceppava, era importante segnalare l’errore. Oggi però lo ignorano tutti!
Valori di ritorno ignorati
Però capite che, se anche la scrittura
non rappresenta un problema, la scrittura
indica invece molto probabilmente un bug!
Il C++ introduce l’attributo
[[nodiscard]], che crea un warning (e blocca la compilazione, se usate-Werror) se ignorate il risultato.
[[nodiscard]]
È sicuramente noioso dover scrivere
[[nodiscard]]prima dei tipi di ritorno di funzioni e metodiPerò mette al riparo da errori che sono impossibili in altri linguaggi. Ad esempio, in Ada è sempre un errore ignorare un valore di ritorno
Volendo si può anche inserire un messaggio:
[[nodiscard]]
Ho modificato il testo originale degli esercizi di Carminati in modo che vi venga suggerito di usare
[[nodiscard]].Ad esempio, la funzione per calcolare la media è dichiarata così nel file
.h:È sufficiente usare
[[nodiscard]]nel file.h: non c’è bisogno di ripeterlo nella definizione all’interno del file C++.
Uso di argc e argv
Linea di comando
I parametri
argceargvpassati come argomenti almainservono per leggere parametri passati dalla linea di comando, come nel caso seguente:Si possono dichiarare in più modi, tutti equivalenti:
Significato di argc e argv (1/2)
Il primo parametro (
argc) contiene il numero di parametri, incluso il nome dell’eseguibile.Il parametro
argvè una lista di puntatori a caratteri (ossia stringhe) che contengono il nome dell’eseguibile seguito dal resto.Di conseguenza,
argv[0]contiene il nome del programma eseguibile, mentre tutti i parametri passati da linea di comando sono memorizzati inargv[1],argv[2], etc.
Significato di argc e argv (2/2)
Se eseguiamo più volte il programma, ecco il suo output:
$ ./args-example
argc = 1
argv[0] = "./args-example"
$ ./args-example 10
argc = 2
argv[0] = "./args-example"
argv[1] = "10"
$ ./args-example 10 1941.txt
argc = 3
argv[0] = "./args-example"
argv[1] = "10"
argv[2] = "1941.txt"Uso di Makefile
Compilare un programma (1/3)
Prendiamo questo semplice esempio:
Compilare un programma (2/3)
Sinora abbiamo mostrato esempi in cui tutto il codice sorgente è in un unico file. Questo non è però utile, perché in futuro dovrete riciclare spesso parti di codice!
Anziché usare le funzioni di copia-e-incolla, è meglio suddividere il codice in più file con estensione
.cpp, che dovranno però poi essere compilati uno a uno e «combinati» insieme (il termine esatto è linking).In questo corso vi obblighiamo ad usare uno strumento piuttosto vetusto ma presente su qualsiasi sistema Unix: GNU Make.
Compilare un programma (3/3)
Partiamo da un caso molto semplice (l’esercizio 1.2 sarà più complicato). Create un file con nome
Makefile(attenzione alla maiuscola iniziale!), e scrivete queste righe al suo interno:Infine, da linea di comando eseguite il comando
make($indica il prompt):$ make g++ -std=c++23 -g3 -Wall -Wextra -Werror --pedantic main.cpp -o main $ ls main main.cpp Makefile
Flag del compilatore
È utile specificare dei flag aggiuntivi per la compilazione, tramite la riga
-std=c++23abilita le caratteristiche più recenti (2023) del C++.-g3: se il codice va in crash, stampa la riga di codice che ha causato l’errore.-Wall -Wextra: rende il compilatore C++ più brontolone del solito.--pedantic: lo rende ancora più brontolone.-Wextra: impedisce di compilare se ci sono warning (molto utile!)
Spiegazione del comando make
Il comando
makeserve per «creare» (appunto, to make) dei file partendo da altri. Con la scrittasi dice a Make che si vuole creare il file
main(eseguibile) partendo dal filemain.cpp.Make sa che i file con estensione
.cppsono programmi C++, e quindi correttamente invoca l’eseguibileg++, passandogli i parametri nella variabileCXXFLAGS.
Comandi personalizzati
Se si vuole fornire manualmente la lista dei comandi da inviare, bisogna scriverli nella riga successiva
Questa seconda riga va indentata obbligatoriamente inserendo un carattere TAB, solitamente indicato sulle tastiere con ↹ (è a sinistra del tasto Q):
Attenzione: se usate uno o più spazi anziché il TAB,
makedarà errore!
Esecuzione di un Makefile
Se eseguiamo immediatamente
makeuna seconda volta, avviene una cosa interessante:$ make $In questo caso, Make non fa nulla: ha controllato le date dei file
mainemain.cpp, e ha visto che il primo è stato creato dopo il secondo: quindi non c’è bisogno di compilare nuovamente il programma.Se voleste obbligare
makea saltare il controllo delle date e ricreare tutto da capo, basta invocarlo così:make -B.
Usare più file sorgente
Nell’esercizio 1.2 si richiede di dividere il programma tra più file, e di compilarli separatamente. In questo caso la struttura del
Makefilesi complica:esercizio1.2: esercizio1.2.cpp funzioni.cpp # Con \ si può andare a capo g++ esercizio1.2.cpp funzioni.cpp \ -o esercizio1.2 $(CXXFLAGS)Questo esempio crea di nuovo l’eseguibile a partire da file
.cpp.Quanto scritto qui sopra funziona, ma non è quanto richiesto dall’esercizio: bisogna esplicitare anche il passaggio intermedio, ossia la creazione di file
.o.
Creare i file oggetto (.o)
L’esercizio 1.2 richiede di esplicitare le dipendenze «intermedie».
Questo è ciò che serve per i file
.o:esercizio1.2: esercizio1.2.o funzioni.o g++ esercizio1.2.o funzioni.o -o esercizio1.2 esercizio1.2.o: esercizio1.2.cpp funzioni.h g++ -c esercizio1.2.cpp -o esercizio1.2.o $(CXXFLAGS) funzioni.o: funzioni.cpp funzioni.h g++ -c funzioni.cpp -o funzioni.o $(CXXFLAGS)(
CXXFLAGSnon serve quando si mettono insieme più file.o: la compilazione del codice C++ è già avvenuta).
Variabili automatiche
GNU Make definisce alcune variabili speciali, dette automatiche,
che semplificano la scrittura del Makefile.
| Variabile | Significato | Trucco |
|---|---|---|
$@ |
File da creare | Il simbolo @ è quello delle email, quindi è come
l’«indirizzo» di destinazione di una lettera |
$^ |
Lista dei file dipendenti | Il simbolo ^ ricorda la freccia ↑, che indica la riga
precedente in cui c’è la lista di file dipendenti |
$< |
Primo file dipendente | Il simbolo < ricorda la freccia ←, che indica la
posizione del primo elemento nella lista |
Variabili automatiche
L’esempio nella slide precedente si può riscrivere così:
È più facile riciclare il
Makefilenei nuovi esercizi!
Eseguire comandi
Da decenni c’è la prassi di usare
makenon solo per generare file, ma anche per eseguire comandi arbitrariAd esempio, capita spesso che programmi richiedano argomenti complessi dalla linea di comando:
$ ./mio-programma 10 "pippo" 1.63413 output_dir/resultsNon sempre è facile ricordarsi come fare per eseguire un programma!
Uso di file fittizi
Se ripensiamo alla struttura dei
Makefile, vediamo che essi sono già in grado di eseguire programmi:È prassi antica chiedere a
makedi creare file “fittizi”, che in realtà non vengono creati, semplicemente per obbligaremakead eseguire una serie di programmi:Scrivendo
make clean, il comandorm -f *.o *.backupviene eseguito:$ make clean rm -f *.o *.backup $
File fasulli
Il meccanismo potrebbe fallire però se qualcuno creasse un file chiamato proprio
cleannella directory in cui lavorate!In questo caso,
make cleanvedrebbe checleangià esiste, e non farebbe nullaSi può ovviare a questo problema con la sintassi seguente:
File multipli ed header
Funzionamento degli #include
I comandi che iniziano con
#storicamente venivano analizzati da un programma separato,cpp, invocato prima del compilatore. (Oggi non è più così, ma dal punto di vista concettuale non cambia).Il programma
cppfa una semplice sostituzione testuale, e non capisce praticamente nulla del linguaggio.Il video seguente mostra che un file
include.hnon deve neppure essere sintatticamente valido: basta che, una volta “espanso” concpp, il programma principale sia corretto.
File multipli ed header
Includete sempre nei vostri file tutti gli
#includeche servono!Ad esempio, se un file
main.cppcontiene questi#include:// main.cpp #include "vectors.h" // Define 3D vectors #include "newton.h" // Define functions to solve Newton's problemsè buona cosa includere comunque
vectors.hanche dentronewton.h:
Motivo #1
Programmi complessi usano moltissimi
#include. In questo caso si tende a inserirli in ordine alfabetico, per individuare duplicati:Formattatori automatici di codice come
clang-formatriordinano gli#include, mettendonewton.hprima divectors.h: errore!
Motivo #2
Ogni
#includerichiede tempo per la compilazione. Di tanto in tanto nei progetti si fa un purge degli#includeinutili: in ogni file, si controlla se ci sono degli header che definiscono cose non usate all’interno del file.Ad esempio, una riga
#include "mp3.h"all’interno di un file sorgente in cui non si toccano affatto file MP3!Nel nostro caso, i vettori definiti in
vector.hpotrebbero non essere mai usati esplicitamente inmain.cpp, magari perché in esso si calcola semplicemente il periodo orbitale di un satellite artificiale. Ma se ci sono dipendenze nascoste (comenewton.hche dipende davector.h), questo è un problema!
Avvertenza su GNU Make
Quando avrete svolto gli esercizi di questa lezione, vi sarà chiaro che la scrittura del
Makefileè un processo lungo e verboso.Il comando
makeè stato inventato nel 1976 da Stuart Feldman, e funzionava su un computer PDP-11 (vedi slide seguente).Oggi più nessuno (neppure io!) usa GNU Make direttamente per compilare codice C++. Per i vostri progetti futuri (oltre questo corso) vi converrà usare sistemi più evoluti ed agili; tra questi, il più usato in assoluto è CMake.
Il PDP-11

|
|
Uso di CMake
CMake è lo standard de facto per compilare progetti in C/C++, e si basa su GNU Make. Il modo in cui si usa è il seguente:
- Si scrive un file chiamato
CMakeLists.txt - Si esegue
cmakeda linea di comando: esso leggeCMakeLists.txte produce un file contenente i comandi da compilare in un sistema scelto dall’utente. - Si eseguono i comandi da compilare nel sistema prescelto.
- Si scrive un file chiamato
Anche se oggi esistono sistemi più veloci e performanti di Make (come Ninja, che è usato per compilare Google Chrome e Android), è possibile chiedere a CMake di produrre un
Makefile.