C++, Python, Julia
Maurizio Tomasi (maurizio.tomasi@unimi.it)
Università degli Studi di Milano

https://ziotom78.github.io/tnds-tomasi-notebooks/tomasi-c++-python-julia.html
C++
Funzionamento di un compilatore
- Un compilatore è un traduttore, che converte un linguaggio in un altro.
- I compilatori C++ come
g++eclang++convertono il C++ in linguaggio macchina. - Per capire come funziona un compilatore, bisogna comprendere il linguaggio macchina delle CPU.
Cosa fa la CPU
- Esegue sequenze di istruzioni
- Accede a periferiche attraverso dei bus
- Accede alla memoria: fondamentale!
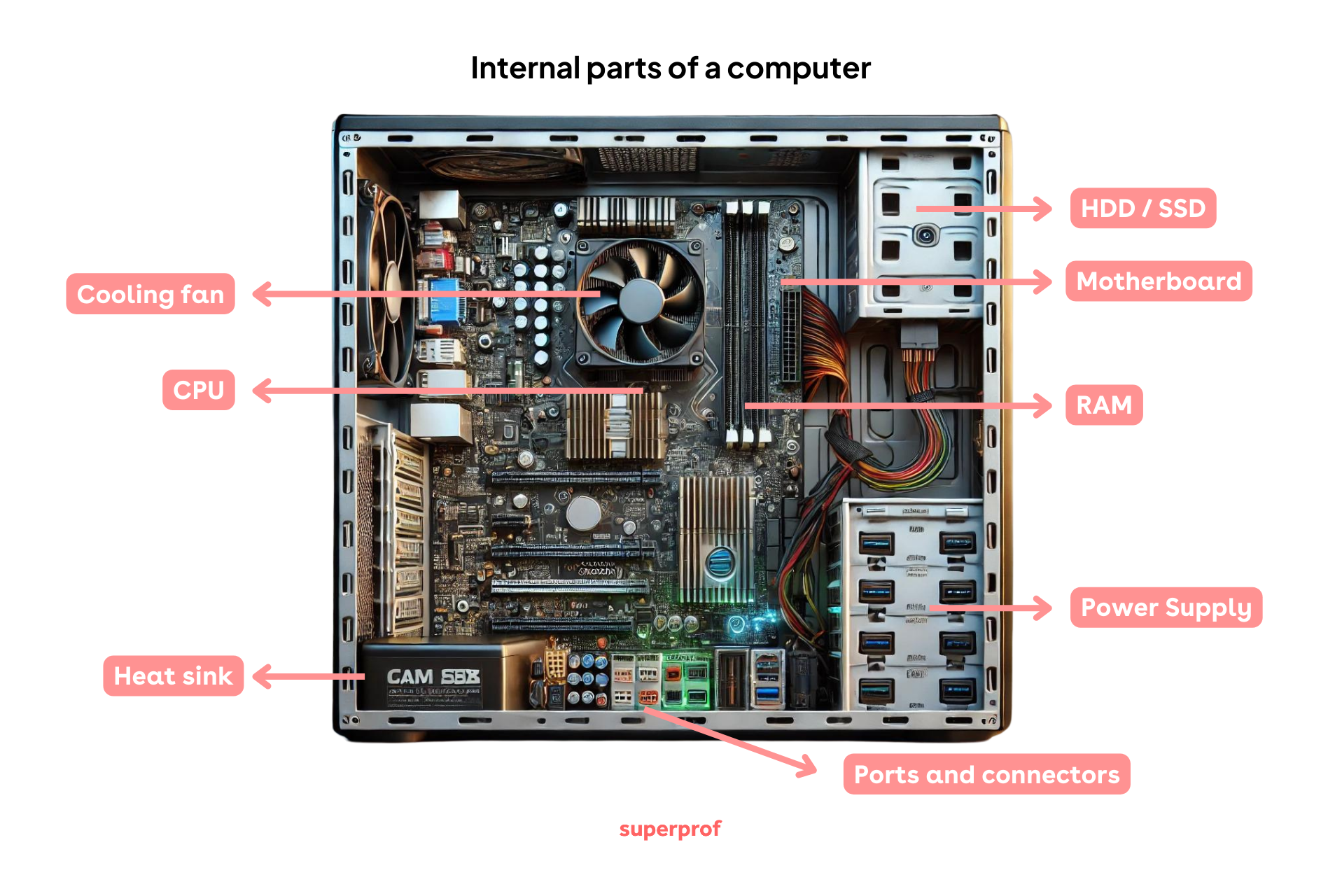
Tipi di memoria
- Memoria volatile:
- Registro (un centinaio di byte, 64 bit/ciclo)
- Cache (128 kB–128 MB, 40-700 GB/s)
- RAM (4–64 GB, 50 GB/s)
- Memoria permanente:
- Disco fisso SSD (10 GB/s)
- Disco fisso HDD (120 MB/s)
Memoria volatile
- Registri
-
Attraverso identificativi come
ebp,rsp,eax… (interi),xmm0,xmm1, … (floating point) - Cache
-
Esclusiva pertinenza della CPU!
- RAM
-
RAM: la CPU richiede il dato al bus della memoria specificando l’indirizzo numerico
 |
Registri (<1 kB) |  |
 |
RAM (8 GB) |  |
 |
HD SSD da 1 TB |  |
Cosa sa fare la CPU?
- Calcoli elementari su interi
- Calcoli elementari su floating-point
- Confronti
- Istruzioni di salto (
goto) - Copia di dati da RAM a registri e viceversa
- Comunicazione attraverso i bus: hard disk, scheda grafica, tastiera, mouse, porte ethernet, etc.
Cosa non sa fare la CPU?
- Cicli
for - Operazioni matematiche complesse (es.,
2 * x + y / z) - Gestione di dati complessi (array, stringhe, etc.)
- Allocazione di memoria con
newedelete - Funzioni con parametri
- Classi
- Molto altro!
Assembler
Un programma in linguaggio macchina è una sequenza di bit:
0110101110…Può essere «traslitterato» partendo dal linguaggio assembler (usando compilatori come NASM e YASM):
Compilare da assembler a linguaggio macchina (e viceversa) assomiglia a una «traslitterazione», come «πάντα ῥεῖ» ↔︎ «pánta rheî», più che a una «traduzione»
In passato, per molti computer era necessario programmare direttamente in Assembler (ossia in linguaggio macchina). Solo poche macchine offrivano nativamente linguaggi ad alto livello, come il Commodore 64:
![]()
Ma già dagli anni ’50 si erano sviluppati linguaggi ad alto livello, come Lisp e Fortran, i cui compilatori traducono (questa volta sì!) il codice in linguaggio macchina

Compilatori
- Un compilatore traduce il codice di un linguaggio ad alto livello (come il C++) in codice macchina
- Trasforma cicli
forin cicli più semplici che la CPU può eseguire - Decide quando usare i registri e quando la RAM
- Il compilatore deve conoscere l’assembler di ogni architettura.
Quelle più diffuse sono:
- x86_64: usata nella maggior parte dei desktop e dei laptop
- ARM: usata soprattutto nei cellulari e nei tablet, ma anche in console di gioco (Nintendo Switch) e alcuni laptop (Chromebooks). Anche i chip Apple M1/M2/M3/M4 sono di questo tipo
Compilatori
Fino agli anni ’90 i compilatori non producevano codice macchina efficiente
Spesso un programmatore con una minima infarinatura di assembler poteva scrivere codice più efficiente!
Alcuni versioni dei compilatori C/C++/Pascal offrivano la possibilità di inserire codice assembler direttamente all’interno di programmi scritti in altri linguaggi!
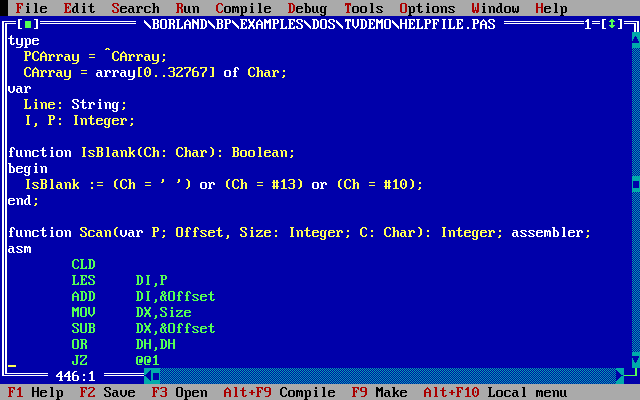
Esempio di codice Assembler (in verde) all’interno di un programma Pascal (Borland Pascal 7.0).

(Byte magazine, Febbraio 1989)
Esempio
Nel Capitolo 8 del bel libro di Bolboacă & Deák “Debunking C++ myths”, gli autori raccontano che negli anni ’90 riuscirono tramite l’assembler a rendere più veloce un loro programma C++
Il programma doveva effettuare in modo efficiente una moltiplicazione di un intero per il numero 320. Il compilatore generava un banale prodotto, ma gli autori si accorsero che 320 = 256 + 64 = 2^8 + 2^6 (vedi i dettagli nel testo), e sfruttarono operazioni sui bit per rendere il prodotto più veloce
Ricompilando il loro vecchio codice ai giorni nostri (il libro è del 2024), gli autori hanno constatato che i compilatori moderni riescono a generare codice ancora più furbo e veloce del loro!
Compilatori
Come mostra l’esempio di Bolboacă & Deák, oggi siamo in una situazione completamente rovesciata!
Da un lato, le CPU più recenti usano ottimizzazioni molto complesse, ed è quindi difficile per un programmatore umano scrivere codice assembler che sfrutti efficientemente la macchina…
…e d’altra parte i compilatori moderni sono così sofisticati da produrre codice macchina imbattibile!
Scrivere codice assembler è quindi una cosa che oggi non è quasi mai necessaria, anche perché rende il codice poco portabile. (Ma ci sono eccezioni, come FFmpeg…)
Esplorare il codice assembler
- Molti compilatori possono produrre file di testo con l’assembler generato, prima della traduzione in linguaggio macchina
- Se usate
gcceclang, esiste il flag-S - Potete fare esperimenti online sul sito godbolt.org (che ho usato per le prossime slide)
Esempio: un ciclo for
Uso di registri
Per ogni dato, il compilatore deve decidere se usare un registro o la RAM: nell’esempio,
nera nella RAM mentreiin un registro (eax)Trovare la scelta ottimale è molto difficile (vedi Wikipedia)
In passato il C/C++ supportava la keyword
register(rimossa col C++17):
Produrre codice assembler
- Il compilatore
g++si basa su GCC, che implementa una serie di algoritmi per capire quale sia il modo più performante di usare i registri e ordinare le istruzioni - Il compilatore
clangsi basa sulla libreria LLVM, che prende in input una descrizione «ad alto livello» della sequenza di operazioni da eseguire e le traduce in codice assembler ottimizzato
Altri linguaggi
- GCC supporta molti linguaggi
oltre al C++, usando lo stesso generatore di codice assembler: C e
Objective-C (
gcc), D (gdc), Go (gccgo), Fortran (gfortran), Ada (gnat). - La libreria LLVM è impiegata da molti compilatori: clang (C/Objective-C/C++), LDC (D), flang (Fortran), Crystal, Swift, Rust, Julia
- Altri compilatori implementano un proprio generatore di codice assembler: FreePascal, DMD (D), Go, Visual Studio (C/C++), etc.
- Alcuni linguaggi, come Nim, producono codice C, che va poi compilato da un compilatore C.
Python
L’approccio di Python
- Python nasce all’inizio degli anni 90, 20 anni dopo il C e 7 dopo il C++
- Quando nasce il Python c’è la consapevolezza che i computer saranno sempre più veloci: programmi «lenti» sono sempre meno un problema
- L’approccio di Python è completamente diverso rispetto al C++: non è più compilato, ma interpretato
- In campo scientifico si usa molto la distribuzione Anaconda Python
Confronto C++/Python
| C++ | Python |
- Il programma Python è più veloce da scrivere e più semplice da leggere
- Il programma C++ richiede 11 ms per l’esecuzione, quello Python 350 ms (30 volte più lento!)
Velocità di Python
- Python non crea programmi nel linguaggio macchina della CPU, ma nell’assembler di una macchina virtuale (la «Python virtual machine»)
- Questo codice non viene eseguito dalla CPU ma da un programma C, che interpreta le istruzioni e le esegue una alla volta
- Questo approccio è più lento, ma ha alcuni vantaggi significativi: vediamoli in un esempio pratico
Tipi e codice macchina
In C++, una istruzione come
x = a + b, seaebsono interi, può essere convertita in Assembler così:Ma se
aebsonodouble, diventa così:
Consideriamo ora questo programma Python:
Come può Python compilare in un linguaggio assembler la funzione
add, visto che la somma può assumere significati diversi?La risposta è che Python non produce un vero assembler, ma un “assembler virtuale”, più astratto perché non legato a dell’hardware specifico!
Compilazione e Python
In Python, l’istruzione
x = a + bviene sempre compilata così:Questi comandi assumono che ci sia un vettore di elementi (chiamato stack) che venga mantenuto durante l’esecuzione, e che
load_fastestore_fastaggiungano e tolgano elementi in coda al vettore.Istruzioni come
binary_addtolgono uno o più elementi in coda al vettore, fanno un’operazione su di essi, e mettono il risultato in coda al vettore
Per eseguire il file test.py, occorre sempre chiamare
python3:
Il programma python3 è scritto in C, ed è più o meno
fatto così:
Cosa fa run_command
La funzione
run_commandesegue una istruzione, e ogni volta che viene invocata deve capire come operare in base al tipo di dato.Verosimilmente, a seconda del comando che deve eseguire,
run_commandchiama una funzione C che gestisce l’esecuzione di quel particolare comando (load_fast,store_fast,binary_add, …)
Questa è una possibile implementazione per
binary_add:
void binary_add(PyObject * val1,
PyObject * val2,
PyObject * result) {
if (isinteger(val1) && isinteger(val2)) {
/* Sum two integers */
int v1 = get_integer(val1);
int v2 = get_integer(val2);
result.set_type(PY_INTEGER)
result.set_integer(v1 + v2);
} else if (isreal(val1) && isreal(val2)) {
/* Sum two floating-point numbers */
} else {
/* ... */
}
}Vantaggi di Python
- Si esegue il codice senza bisogno di compilare prima → più facile fare il debug
- Non è necessario dichiarare variabili → codice più breve e veloce da scrivere
- Non si usano i file header (
.h) → meno file da gestire - Non si usano i Makefile → maggiore semplicità
- Niente puntatori → minore possibilità di crash
Svantaggi di Python
Se le variabili non hanno tipo, sono possibili molti errori
Quasi tutti gli errori capitano durante l’esecuzione: è quindi più facile che vada in crash un programma Python piuttosto che un programma C++. Esempio:
$ python3 test.py Computing results… Please wait! Traceback (most recent call last): File "/home/tomasi/test.py", line 1429, in <module> print_results(results) NameError: name 'print_results' is not definedI programmi sono molto più lenti del C++!
Comodità di Python
- Python non viene certo usato per scrivere codice che funziona velocemente, ma per scrivere codice rapidamente!
- A differenza del C++, il linguaggio supporta molte funzionalità di alto livello
Esempio
Supponiamo di avere un file,
test.txt, contenente questi dati:# This is a comment # # sensor temperature upper_flange 301.76 lower_flange 270.1 horn 290.81 detector 85.3Esso contiene delle temperature registrate da termometri installati in uno strumento
Vogliamo scrivere un programma che stampi a video i nomi dei sensori, ordinati secondo la temperatura dal più freddo al più caldo. Il codice deve ignorare spazi, commenti e linee vuote
Soluzione dell’esercizio
with open("test.txt", "rt") as inpf:
lines = [x.strip() for x in inpf.readlines()] # lines = { x.strip | x ∈ inpf.readlines }
# Remove from "lines" empty lines and comments
lines = [x for x in lines if x != "" and x[0] != "#"]
# Split each line in two
pairs = [x.split() for x in lines]
for sensor, temp in sorted(pairs, key=lambda x: float(x[1])):
print(f"{sensor:20} (T = {temp} K)")detector (T = 85.3 K)
lower_flange (T = 270.1 K)
horn (T = 290.81 K)
upper_flange (T = 301.76 K)Quando usare Python?
- Se un programma non richiede molti calcoli complessi, Python è solitamente la scelta migliore
- Se un programma Python è 100 volte più lento di un programma C++, ma completa sempre l’esecuzione in 0,1 secondi, vale la pena velocizzarlo?
- Scrivere programmi in Python è molto più veloce che scriverli in C++
Python nel calcolo scientifico
- È possibile usare Python per simulazioni Monte Carlo? O per calcoli numerici su milioni di elementi?
- Python permette di invocare funzioni scritte in C e in Fortran
- Negli anni sono state sviluppate librerie Python molto potenti per il calcolo scientifico: NumPy, Numba, Taichi, f2py, Cython, Dask, Pandas…
- Lo svantaggio è che queste librerie scientifiche sono spesso poco integrate col linguaggio
Julia
Cos’è Julia?
- julialang.org
- Linguaggio molto recente (versione 0.1 rilasciata a Febbraio 2013)
- Pensato espressamente per il calcolo scientifico
- Veloce come C++ e facile come Python…?
- Versione corrente: 1.12.5
Dove si colloca Julia?
- Compilatori
-
C, C++, FreePascal, gfortran, Rust, GNAT Ada, Nim, …
- Interpreti
-
CPython, R, Matlab, IDL, …
- Just-in-time compilers
-
Java, Kotlin, C#, LuaJIT, 👉Julia👈, etc.
Un assaggio del linguaggio
Confronto Python/Julia
| Python | Julia |
Julia ha le medesime performance del C++, ma com’è possibile se come per Python in Julia non si specificano i tipi?
Compilazione in Julia
Julia, a differenza di Python, compila il codice in linguaggio macchina. Ma la compilazione viene effettuata la prima volta che si chiede di eseguire una funzione, e solo per i tipi specifici usati in quella chiamata
Per esempio, nel momento in cui si scrive
mysum(1, 2), Julia esegue la compilazione assumendo cheaebsiano due interi.A differenza del C++, la compilazione non viene fatta su un intero file, ma sulle singole funzioni: se una funzione non viene mai chiamata, non viene mai compilata in linguaggio macchina.
Sessione interattiva
Julia e la programmazione OOP
OOP e Julia
Julia non supporta le classi.
L’approccio OOP “alla C++” si è infatti dimostrato negli anni poco adatto per il calcolo scientifico. Consideriamo ad esempio
FunzioneBase, che ci è servita molte volte:e vediamone i limiti nell’ipotesi di voler rendere il codice più versatile.
Propagazione degli errori
Abbiamo visto che, per studiare come gli errori si propagano nel codice, un buon metodo è quello di eseguire una simulazione Monte Carlo
Ma queste simulazioni possono essere molto lente da eseguire, soprattutto se il modello è complesso!
Per certi calcoli sarebbe sufficiente la propagazione degli errori
La classe Measurement
struct Measurement {
double value;
double error;
Measurement(double v, double e) : value{v}, error{e} {}
};
Measurement operator+(Measurement a, Measurement b) {
return Measurement{a.value + b.value, sqrt(pow(a.error, 2) + pow(b.error, 2))};
}
// Do the same for the other operators: -, *, /, sin, cos…Integrali e Measurement
Supponiamo ora che io voglia calcolare lo zero o l’integrale di una funzione derivata da
FunzioneBase.Mi è impossibile usare
Measurementnella nostraFunzioneBase, perché essa lavora solo con il tipodouble:Anche qualsiasi classe derivata deve quindi usare i
double.
Soluzione
Se
FunzioneBasefosse una classe di ROOT (quindi immodificabile), sarei spacciato: non potrei usareMeasurementcon essa!Se invece fossi io l’autore di
FunzioneBase(ed è così!), potrei allora modificare il codice. Ma così non potrei più compilare i miei vecchi programmi che usavano la versione con idouble.Potrei fare una copia della classe e modificare quella, ma se in futuro correggessi bug o apportassi miglioramenti a
FunzioneBase, dovrei ricordarmi di aggiornare entrambe.
Passo successivo
Supponiamo ora di aver implementato una classe
UnitValueche combini valori e unità di misura, e ne verifichi la consistenza:Mi piacerebbe usarla insieme alla mia classe
Measurementche propaga gli errori, ma non posso: siavaluecheerrorsono variabilidouble!Se però modifico
Measurement, rischio che la mia nuova versione diFunzioneBasenon funzioni più!
La soluzione di Julia
In Julia non si definisce il tipo dei parametri: si può quindi passare anche tipi «nuovi» a funzioni «vecchie».
In effetti, questo si può fare con due librerie già esistenti: Measurements.jl e Unitful.jl
using Measurements, Unitful speed = (2.0 ± 0.1)u"m/s" # Use 'u' followed by a string to define the unit start_pos = (3.5 ± 0.1)u"m" time = (6.0 ± 0.5)u"s" final_pos = start_pos + speed / time # ERROR: DimensionError: 3.5 ± 0.1 m and 0.333 ± 0.032 m s^-2 # are not dimensionally compatible. final_pos = start_pos + speed * time # Ok, the result is 15.5 ± 1.2 m
La soluzione del C++
In realtà, anche in C++ è possibile ottenere la versatilità di Julia, ma bisogna abbandonare l’approccio OOP.
Se si definisse
UnitValuecome una classe template, si potrebbe combinare con la classeMeasurement(a patto però di ridefinire anche gli operatori!):Di fatto, le librerie scientifiche moderne in C++ non usano più approcci OOP come ROOT, ma sono basate sui template (Armadillo…)
Omoiconicità di Julia
Julia e le macro
Julia è un linguaggio omoiconico (“medesima rappresentazione”), che significa che il codice è rappresentato come una struttura dati accessibile dal linguaggio stesso.
Questa è una caratteristica mutuata dal linguaggio Scheme, da cui gli sviluppatori di Julia hanno preso spesso ispirazione. (Il cuore del compilatore di Julia è scritto in un dialetto di Scheme!)
Le macro di Julia sono apparentemente simili alle funzioni del C++, ma hanno una importante differenza (no, non hanno nulla a che vedere con
#define!).
Esempio di funzione
Consideriamo una funzione che accetta come argomento un intero
x, e stampa "A" se x è maggiore
di 2, "B" altrimenti.
| C++ | Julia |
Esempio di macro
Supponiamo ora di affrontare un problema apparentemente simile.
Vogliamo scrivere una funzione che accetta come argomento un parametro
x, e stampa"A"solo sexè stato calcolato usando una somma, altrimenti"B".
Problema col C++
- Dovremmo usare una istruzione
if, ma questa in C++ può essere usata solo per confrontare il valore di variabili - Noi dovremmo invece esaminare le istruzioni usate per
calcolare il valore di
x - Il linguaggio C++ non è «omoiconico», perché i suoi
costrutti (
if,while,for, …) funzionano solo sul contenuto dei dati (variabili), e non sulle istruzioni di codice
Esempio di macro
Julia è invece omoiconico, e quindi si può ispezionare il codice usando gli stessi costrutti del linguaggio che si usano con i dati:
Esecuzione di macro
Le macro vengono eseguite prima che il codice Julia venga tradotto in linguaggio macchina
Possono quindi essere usate per modificare del codice presente nel file sorgente, o addirittura per generarlo automaticamente
Ma una caratteristica simile non è troppo esotica e “accademica”? No, anzi, è straordinariamente pratica! Ma bisogna avere mente aperta per immaginarne le applicazioni…
Latexify.jl
La libreria Latexify traduce la definizione di una funzione Julia in un’espressione LaTeX, che può essere visualizzata con la funzione
render:julia> latex_str = @latexrun f(x; y=2) = (x + 2) / y - 1 julia> println(latex_str) L"$f\left( x; y = 2 \right) = \frac{x + 2}{y} - 1$" julia> render(latex_str)![]()
Il modo in cui
@latexrunopera è quello di esaminare pezzo per pezzo l’espressione, e tradurre le sue operazioni in simboli LaTeX.È utilissima per verificare una formula matematica complessa.
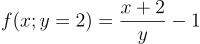
Gestire argc e argv
Un’altra bella applicazione dell’omoiconicità è la generazione di interfacce da linea di comando. Ricordate l’esercizio 6.2 (ricerca degli zeri)?
$ ./esercizio6.2 0 3 100 1e-5 Zero: 0.33333Il codice all’inizio del
mainera il seguente:
Generare il main
La libreria Comonicon.jl (bel nome!) implementa una macro,
@main, che, se fosse scritta per il C++, si userebbe così:La macro
@mainanalizza i parametri dirun_programe genera automaticamente ilmain, usandostodestoiin modo appropriato.
$ ./esercizio6.2 --help
Usage:
fun [REQUIRED,optional-params]
An API call doc comment
Options:
-h, --help print this cligen-erated help
--help-syntax advanced: prepend,plurals,..
-a=, --a= float REQUIRED set a
-b=, --b= float REQUIRED set b
-n=, --nsteps-max= int REQUIRED set nsteps_max
-p=, --prec= float REQUIRED set prec
$ ./esercizio6.2 -a=0 -b=3 --nsteps-max=100 --prec=1e-5
Zero: 0.33333
$ ./esercizio6.2 0 3 100 1e-5
Zero: 0.33333
$Altre applicazioni
Julia rende semplice l’implementazione della differentiable programming, in cui si possono calcolare automaticamente derivate esatte di funzioni o addirittura interi programmi, usando le macro e l’omoiconicità
Un campo in cui Julia sta prendendo sempre più piede è quello dell’intelligenza artificiale: la differenziabilità è molto utile per ottimizzare reti neurali complesse
Anche se è un concetto vecchio (è nato col LISP, che risale agli anni ’50!), l’enorme potenziale dell’omoiconicità non è stato probabilmente ancora ben sfruttato
Svantaggi di Julia
Al momento è ancora molto complicato produrre degli eseguibili stand-alone (come il C++), il che rende complesso far girare programmi Julia su cluster HPC.
Le librerie Julia tendono a “rompersi” facilmente quando escono a nuove versioni del linguaggio. (Ad esempio, Comonicon.jl non funziona con la versione più recente di Julia!)
Il fatto che il compilatore debba sempre compilare in tempo reale le funzioni lo rende a volte lento nel “rispondere”, soprattutto se confrontato con Python.
Alcuni paradigmi (es., il multiple dispatch, l’abbandono delle classi…) può richiedere uno sforzo significativo per chi viene da una esperienza di programmazione tradizionale ad oggetti.
Approfondimento di Julia
- Nel video Julia, the power of language (youtu.be/Zb8G6T8JtuM), lo speaker mostra varie applicazioni di Julia, tra cui l’implementazione di un tipo di matrice con determinate simmetrie
- In un altro video Alan Edelman and Julia Language (youtu.be/rZS2LGiurKY), lo speaker spiega come calcolare efficacemente derivate con Julia
Conclusioni
Vi fornisco alcune regole generali per scegliere il linguaggio da usare nel vostro prossimo progetto:
C++: Programmi che devono girare molto velocemente e devono essere estremamente robusti; potenzialmente potreste volerli far girare anche tra anni.
Python: script che risolvono i piccoli problemi quotidiani, produzione di grafici e tabelle, uso di pacchetti Python standard (Intelligenza Artificiale…)
Julia: ricerca scientifica, nuovi modelli fisici, prototipi che richiedono elevata velocità di calcolo